Data Science è una disciplina interdisciplinare che utilizza metodi scientifici, algoritmi e sistemi per estrarre conoscenza e intuizioni dai dati in varie forme, sia strutturate che non strutturate. Essa combina aspetti di matematica, statistica, informatica e conoscenza del dominio per analizzare e interpretare grandi volumi di dati. Con l’obiettivo di aiutare le organizzazioni nel prendere decisioni basate sui dati, la Data Science è fondamentale in molti settori, inclusi affari, governo, scienze sociali, medicina e altri. Attraverso l’utilizzo di tecniche di data mining, machine learning e visualizzazione di dati, i Data Scientist trasformano dati complessi in informazioni chiare, scoprendo pattern e insights che guidano l’innovazione e le strategie efficienti.
Machine Learning – Data Science
Nel panorama dello sviluppo software, due approcci distinti si contendono il primato: la programmazione tradizionale e il machine learning. Entrambi offrono soluzioni differenti, con caratteristiche e vantaggi peculiari.
La programmazione tradizionale, basata sull’esplicita codifica di istruzioni da parte del programmatore, rappresenta un metodo consolidato e affidabile. Il programmatore assume il controllo completo del software, definendone il comportamento passo dopo passo. Tale approccio si rivela particolarmente efficace per compiti ben definiti e ripetitivi, garantendo efficienza e prevedibilità. Tuttavia, la complessità intrinseca nella scrittura di codice complesso può ostacolare la flessibilità e l’adattamento a nuove esigenze.
Il machine learning, invece, rivoluziona il paradigma, delegando al software la capacità di apprendere autonomamente dai dati. Attraverso l’analisi di un set di dati predefinito, il software elabora un modello che gli permette di fare previsioni o classificare nuovi dati. L’adattabilità e l’apprendimento automatico si configurano come i punti di forza del machine learning, rendendolo ideale per compiti complessi e in continua evoluzione. Tuttavia, la complessità del processo di apprendimento e la difficoltà di interpretare le decisioni del software possono rappresentare ostacoli da non sottovalutare.
Quale approccio scegliere? La risposta dipende dalle specificità del progetto. La programmazione tradizionale si candida come scelta ottimale per compiti ben definiti e ripetitivi, mentre il machine learning brilla quando l’adattabilità e l’apprendimento automatico assumono un ruolo chiave.
In un futuro sempre più interconnesso, la programmazione tradizionale e il machine learning non saranno più alternative inconciliabili, ma due strumenti complementari da utilizzare in sinergia per dar vita a software sempre più potente e versatile.
In questa sinergia, la programmazione tradizionale fornirà la struttura e la robustezza necessarie, mentre il machine learning infonderà l’intelligenza e l’adattabilità che permetteranno al software di evolversi e rispondere alle sfide sempre più complesse del mondo che ci circonda. (Data Science)
Big Data – Data Science
L’avvento dei Big Data, ossia l’enorme mole di dati generata quotidianamente da diverse fonti, ha rivoluzionato il panorama dell’informatica. La gestione e l’analisi di questi dati assumono un’importanza cruciale per estrarre informazioni utili e ottenere un vantaggio competitivo e le tecniche sono studiate nella materia del data science.
In questo contesto, si delinea una distinzione fondamentale: dato strutturato vs. dato non strutturato.
I dati strutturati si caratterizzano per una forma organizzata e ben definita, facilmente memorizzabile e analizzabile. Tipici esempi sono i fogli di calcolo, i database relazionali e i file CSV. La loro rigidità facilita l’analisi con strumenti tradizionali, garantendo velocità e accuratezza.
Al contrario, i dati non strutturati si presentano in una forma libera e non predefinita, privi di una struttura rigida. Immagini, video, testi e email sono esempi lampanti di questa categoria. La loro analisi risulta più complessa e richiede l’utilizzo di tecniche avanzate di machine learning e intelligenza artificiale.
Comprendere le differenze tra queste due tipologie di dati è fondamentale per:
- Scegliere gli strumenti di analisi adeguati: algoritmi statistici per i dati strutturati e tecniche di machine learning per quelli non strutturati.
- Ottimizzare l’archiviazione: differenti tecnologie di archiviazione sono adatte a seconda della struttura del dato.
- Estrarre informazioni utili: l’analisi di entrambi i tipi di dati può fornire una visione completa e olistica di un problema.
I Big Data offrono un enorme potenziale, ma la loro gestione richiede competenze specifiche e tecnologie all’avanguardia. La distinzione tra dati strutturati e non strutturati rappresenta il primo passo per comprendere e sfruttare al meglio questa preziosa risorsa.
L’obiettivo ultimo è quello di trasformare i dati in conoscenza, una conoscenza che può guidare decisioni strategiche, migliorare l’efficienza dei processi e creare nuove opportunità di business. Nel contesto del data science, la padronanza delle diverse tipologie di dati e delle tecniche di analisi rappresenta un fattore chiave per il successo in un mondo sempre più data-driven.
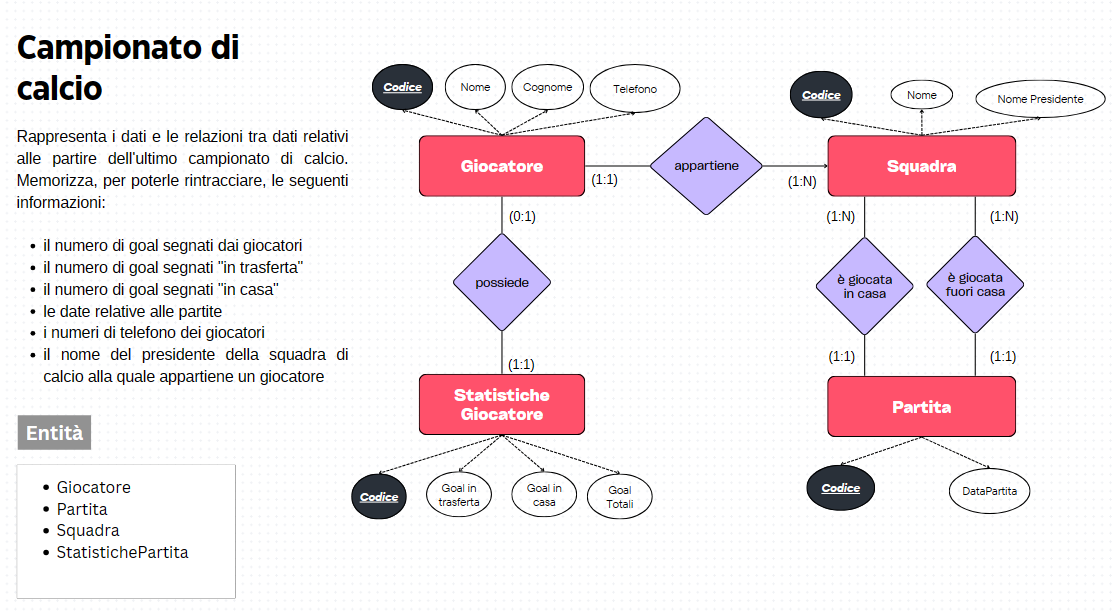
5V – Data Science
L’esplosione del volume di dati generati ha portato all’introduzione del concetto di Big Data, caratterizzato da cinque dimensioni chiave: Volume, Velocità, Varietà, Veridicità e Valore. Nel data science Conosciute come le 5V, queste dimensioni definiscono le proprietà intrinseche che rendono i Big Data unici e complessi da gestire.
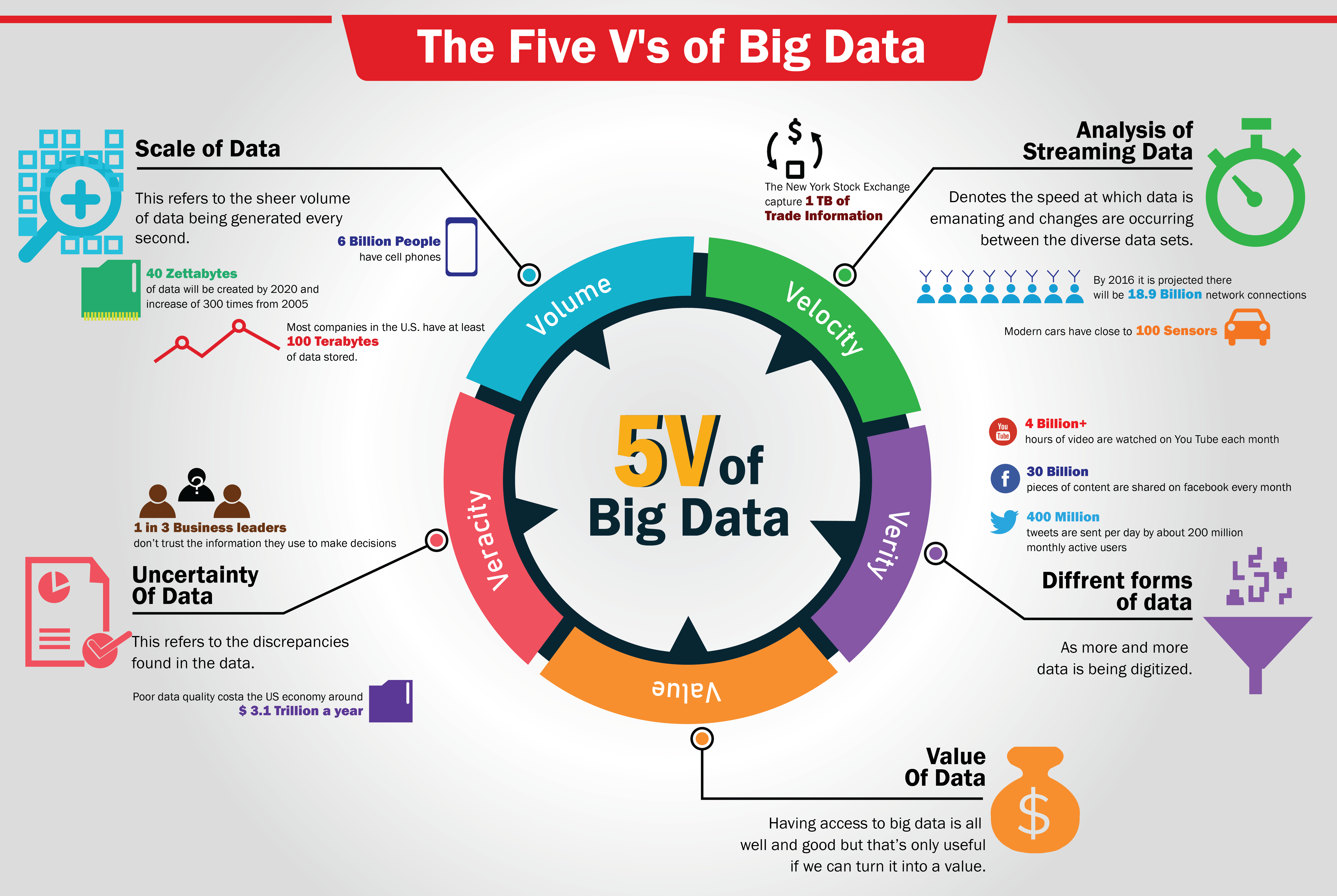
Volume
La prima V si riferisce alla quantità di dati in continua crescita. Si pensi ai miliardi di file generati ogni giorno da social media, sensori IoT, transazioni online e altre sorgenti. La gestione di volumi così vasti richiede tecnologie di archiviazione e di elaborazione dati scalabili e performanti. I volumi di dati possono essere generati dalle seguenti fonti:
- Social media: Ogni giorno, su Facebook vengono pubblicati oltre 2 miliardi di post, 350 milioni di foto e 100 milioni di ore di video.
- Internet of Things (IoT): Si stima che entro il 2025 ci saranno oltre 75 miliardi di dispositivi connessi all’IoT in tutto il mondo.
- Transazioni finanziarie: Ogni giorno vengono effettuate oltre 400 miliardi di transazioni finanziarie a livello globale.
- Ricerca scientifica: Il Large Hadron Collider (LHC) del CERN genera circa 15 petabyte di dati al giorno.
Per mettere in prospettiva la quantità di dati:
- 1 petabyte equivale a 1 milione di gigabyte.
- 1 exabyte equivale a 1 milione di petabyte.
- 1 zettabyte equivale a 1 milione di exabyte.
Velocità
La velocità nei Big Data si riferisce alla capacità di elaborare, trasmettere e analizzare i dati in tempo reale o quasi reale. Questo aspetto è cruciale in contesti in cui le decisioni devono essere prese istantaneamente, come nel mondo degli affari, nelle reti sociali, nella salute e nell’industria. Con l’aumento esponenziale della quantità di dati generati ogni giorno, la gestione della velocità è diventata una sfida significativa.
Per affrontare la velocità nei Big Data, molte organizzazioni stanno adottando tecnologie di elaborazione in tempo reale. Queste tecnologie consentono l’analisi istantanea dei dati mentre vengono generati, consentendo alle organizzazioni di ottenere informazioni cruciali senza ritardi significativi. Framework come Apache Kafka, Apache Flink e Apache Storm sono diventati pilastri fondamentali in questo contesto, facilitando la gestione di enormi flussi di dati in tempo reale.
Le architetture di data streaming sono progettate per affrontare specificamente il problema della velocità nei Big Data. Invece di elaborare i dati in lotti (batch processing), l’elaborazione in streaming consente di analizzare i dati man mano che arrivano. Ciò consente alle organizzazioni di identificare pattern, tendenze e anomalie in tempo reale. Architetture come Lambda Architecture e Kappa Architecture sono state sviluppate per gestire la complessità dei dati in streaming.
Varietà
Questo termine si riferisce alla diversità di tipi e fonti di dati che le organizzazioni devono affrontare. Mentre il Volume riguarda la quantità e la Velocità la rapidità di generazione, la Varietà sottolinea l’eterogeneità e la complessità dei dati disponibili.
La variabilità nei Big Data è evidente nella vasta gamma di formati e tipi di dati. Oltre ai tradizionali dati strutturati, come quelli presenti nei database relazionali, ci sono dati non strutturati provenienti da fonti come testi, immagini, audio e video. Inoltre, i dati semistrutturati, come i documenti XML o JSON, aggiungono ulteriore complessità all’ecosistema dei Big Data.
La sfida principale legata alla variabilità è rappresentata dalla necessità di unificare e integrare dati eterogenei. Gli sforzi sono concentrati sull’implementazione di soluzioni di integrazione e sullo sviluppo di strumenti che possano gestire la varietà dei dati in modo efficiente. L’approccio tradizionale basato su schemi rigidi è stato sostituito da soluzioni più flessibili, come i database NoSQL e le piattaforme di data lakes, che consentono di immagazzinare e gestire dati di vario tipo senza la necessità di uno schema predeterminato.
L’analisi polistrutturata è diventata cruciale per estrarre significato dai dati variabili. Gli strumenti di analisi avanzata, tra cui l’intelligenza artificiale e l’apprendimento automatico, sono sempre più utilizzati per comprendere e interpretare dati provenienti da diverse fonti. L’analisi testuale, l’analisi delle immagini e la riconoscimento vocale sono solo alcune delle applicazioni di questo approccio polistrutturato.
Veridicità
La veridicità rappresenta un aspetto cruciale dei Big Data, riferendosi all’affidabilità, all’accuratezza e alla fiducia nei dati raccolti e analizzati. In un ambiente caratterizzato dalla grande varietà di fonti e tipi di dati, garantire la veridicità diventa una sfida significativa che influisce direttamente sulla qualità delle decisioni e delle analisi effettuate.
La veridicità è strettamente legata alla qualità dei dati, che può essere influenzata da diversi fattori, tra cui errori di inserimento, duplicati, dati mancanti e altri problemi di integrità. È essenziale che le organizzazioni implementino strategie e processi per garantire la precisione e l’attendibilità dei dati da cui traggono informazioni.
La gestione della qualità dei dati è un elemento fondamentale per assicurare la veridicità nei Big Data. Le pratiche di pulizia, normalizzazione e validazione dei dati sono essenziali per ridurre gli errori e migliorare l’affidabilità complessiva delle informazioni. Strumenti e framework specifici, come Apache Nifi e Talend, possono essere utilizzati per automatizzare questi processi e garantire dati più accurati.
Nel contesto dei Big Data, la diffusione di informazioni errate o manipolate è un rischio da considerare. Le organizzazioni devono essere consapevoli della possibilità di disinformazione e adottare misure per rilevare e mitigare tale fenomeno. L’integrazione di tecniche di analisi delle fonti e di verifica della provenienza dei dati è essenziale per contrastare la disinformazione.
L’implementazione di un solido modello di governance dei dati è fondamentale per garantire la veridicità nei Big Data. Le politiche di gestione dei dati, le procedure di sicurezza e i protocolli di monitoraggio devono essere definiti chiaramente e seguiti attentamente. Inoltre, la formazione del personale riguardo alle migliori pratiche di gestione dei dati contribuisce a mantenere elevati standard di veridicità.
Valore
La creazione di valore rappresenta il cuore dei Big Data, sintetizzando l’obiettivo fondamentale di sfruttare le enormi masse di dati disponibili per ottenere benefici tangibili e informazioni significative. La chiave per estrarre valore dai Big Data risiede nella capacità di trasformare dati grezzi in informazioni significative. L’analisi avanzata, che include tecniche di data mining, machine learning e intelligenza artificiale, permette di identificare pattern, tendenze e relazioni altrimenti nascosti nei dati. L’impiego di algoritmi avanzati consente alle organizzazioni di ottenere insights approfonditi e di prendere decisioni più informate.
La creazione di valore attraverso i Big Data si manifesta anche nella personalizzazione dei prodotti e servizi. Le aziende utilizzano l’analisi dei dati per comprendere meglio le preferenze degli utenti, fornendo esperienze personalizzate che soddisfano le esigenze specifiche di ciascun individuo. La capacità di adattarsi alle preferenze degli utenti è diventata un vantaggio competitivo significativo in molteplici settori.
Fasi del Data Science
La Data Science è una disciplina emergente che combina statistica, informatica e machine learning per estrarre conoscenza da dati complessi e voluminosi. L’obiettivo è quello di trasformare i dati in informazioni utili per supportare decisioni strategiche, migliorare l’efficienza dei processi e creare nuove opportunità di business.
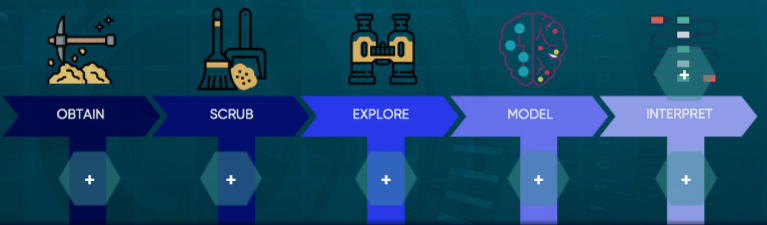
Il paradigma OSEMN, acronimo di Acquisizione, Pulizia (Scrubb), Esplorazione (Explore), Modellazione (Model), e Interpretazione (iNterpret), è un approccio metodologico ampiamente utilizzato nel campo dei Big Data per affrontare le diverse fasi del processo di analisi e sfruttare al meglio il potenziale informativo dei dati. In questo capitolo, esploreremo dettagliatamente ciascuna fase del paradigma OSEMN.
Acquisizione (Obtain)
La fase di Acquisizione rappresenta l’inizio del processo, dove l’obiettivo è raccogliere dati da diverse fonti. Questa fase richiede la comprensione delle fonti disponibili, la selezione dei dati rilevanti e la raccolta di informazioni in modo strutturato. L’acquisizione può coinvolgere sia dati strutturati che non strutturati, provenienti da database, file, sensori o altre fonti.
Pulizia (Scrub)
La fase di Pulizia è dedicata alla preparazione dei dati per l’analisi. Questo processo implica l’identificazione e la correzione degli errori nei dati, la gestione dei valori mancanti e la rimozione di eventuali duplicati. La pulizia dei dati è fondamentale per garantire la qualità e l’affidabilità delle informazioni durante le fasi successive del processo di analisi.
Esplorazione (Explore)
Nella fase di Esplorazione, gli analisti esaminano i dati per identificare pattern, tendenze e relazioni. Questo coinvolge l’uso di tecniche di visualizzazione dei dati, statistica descrittiva e altre analisi esplorative. L’obiettivo è acquisire una comprensione approfondita dei dati e formulare ipotesi che saranno successivamente testate nella fase di Modellazione.
Modellazione (Model)
La fase di Modellazione comporta la creazione e l’implementazione di modelli analitici o algoritmi predittivi. Gli analisti utilizzano tecniche di machine learning e modelli statistici per formulare previsioni o identificare pattern complessi nei dati. Questa fase è cruciale per sfruttare appieno il potenziale predittivo dei Big Data e generare risultati che possono guidare decisioni informate.
Interpretazione (iNterpret)
L’ultima fase, Interpretazione, coinvolge la comprensione e l’interpretazione dei risultati ottenuti dalla fase di Modellazione. Gli analisti valutano la validità dei modelli creati e valutano come le informazioni estratte possano essere applicate in contesti reali. L’interpretazione completa il ciclo del paradigma OSEMN, fornendo una base per decisioni informate e azioni strategiche.
Va notato che il paradigma OSEMN non è un processo lineare nel contesto del data science. Spesso, gli analisti devono iterare attraverso le fasi multiple del paradigma, rifinendo modelli, aggiornando i dati e rivedendo le ipotesi in base ai risultati ottenuti. Questa iterazione continua consente un approccio flessibile e adattabile all’evoluzione dei dati e delle esigenze analitiche nel tempo.
Torna ad Intelligenza Artificiale